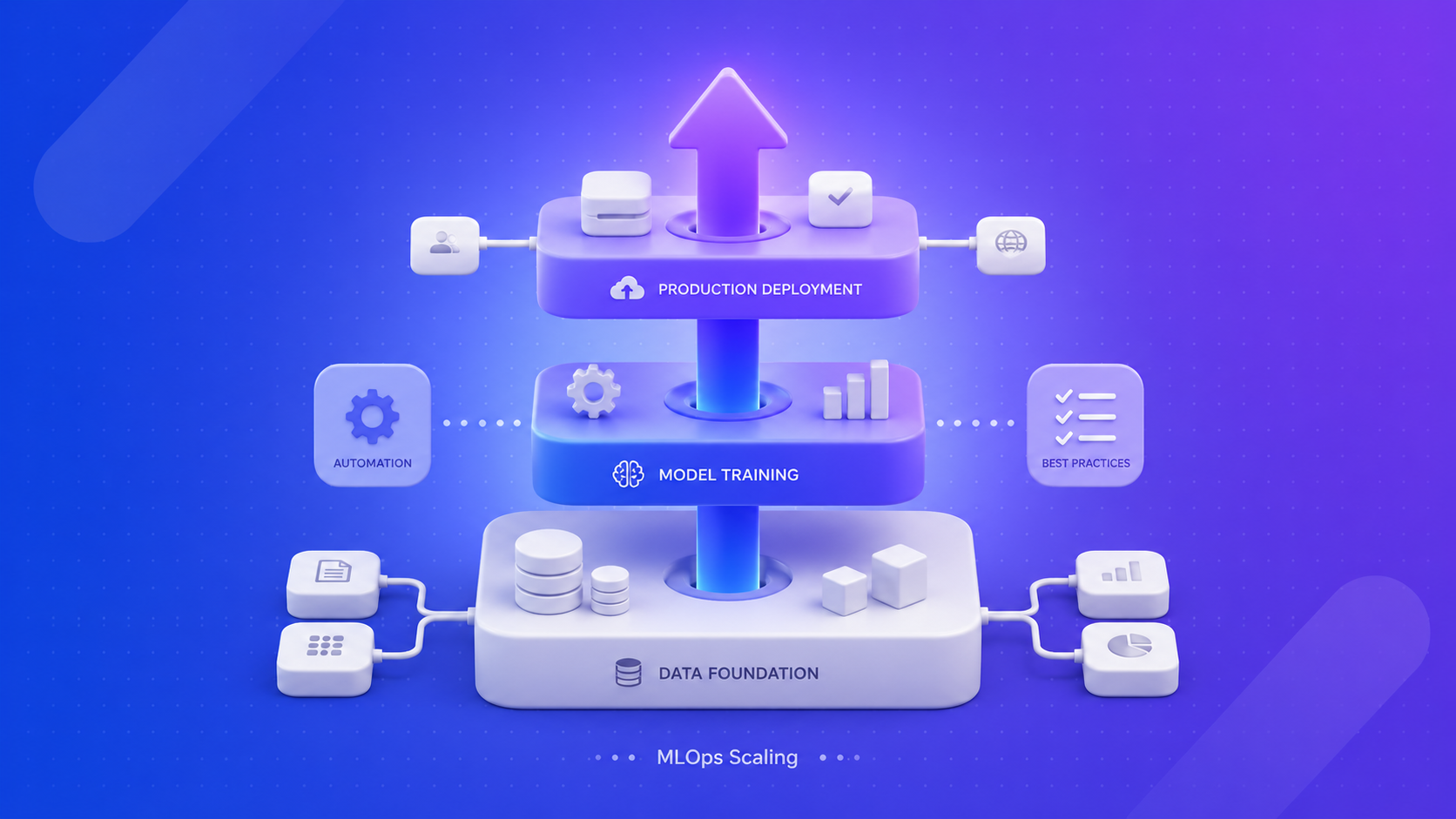
Most ML models stall before production, not because the math is wrong, but because nobody owns the pipeline after training. Versioning, automation, and monitoring are what move models from prototype to live system.
Modern organizations rely on AI for real-time operations, large-scale automation, and faster decision-making. The problem, however, is that insufficient infrastructure, inefficient monitoring, and ineffective operations hinder their efforts to deploy their machine learning models. Here, MLOps comes into play to maintain the innovation cycle and reliability of your models.
Whether you’re implementing or scaling machine learning, an effective ML deployment matters the most. In this guide, we will cover the most effective MLOps best practices and how to approach the deployment. Before we proceed, let’s start by understanding what MLOps actually means and see what comes around.
What is MLOps?
Machine Learning Operations (MLOps) is defined by processes that automate and govern the complete machine learning lifecycle, from ingestion through training, testing, deployment, monitoring, and finally, retraining. This acts as DevOps for AI-powered applications where models grow, and prediction accuracy strongly relies on changing data. MLOps helps data scientists, ML engineers, and IT teams collaborate to keep machine learning models reliable and scalable in production environments.
What Has Changed in 2026?
Contemporary AI-powered applications are increasingly complex and extend well beyond a model that lies behind some API. Production systems have moved from foundation models through retrieval pipelines to fine-tuned adapters and governance layers. At the same time, emerging legislation, such as the EU AI Act, imposes requirements on the transparency and explainability of AI models. Consequently, governance has become one of the crucial components of the MLOps pipeline.
Why MLOps Matters for Scaling ML Applications?
Without MLOps, increasing scale increases risk rather than benefit. According to industry research from Azumo and Dataiku, efficient ML operations can reduce the total cost of ownership in ML lifecycles by approximately 40%, along with fielding 2.5 times as many successful models in production. Here are five reasons MLOps is important to achieve scale:
- Models degrade silently: Accuracy is lost after several weeks without maintenance.
- Hand re-training will not scale: It will be impossible to track twenty models manually.
- Regulatory compliance requires provenance: Oversight expects to know the decision-making process.
- Drift cannot be detected without monitoring: The inputs grow faster than the dashboard refreshes.
- Ownership failures lead to disruption: Ambiguous transitions between teams result in production downtime.
In other words, the absence of MLOps is the difference between good and bad AI investment.
The Core Pillars of Production-Ready ML Operations
There are certain fundamentals that strong ML operations are built upon. These pillars are institutionalized practices on a platform level, not fragmented scripts.
- Comprehensive version control across datasets, features, model artifacts, and prompt configurations.
- Structured ML pipeline orchestration with CI/CD and continuous training workflows.
- Strong offline-online feature consistency to eliminate training-serving data skew.
- Real-time ML observability for drift detection, latency analysis, and data quality monitoring.
- Robust governance frameworks with audit logging, lineage tracking, and role-based access controls.
- Human-in-the-loop intervention mechanisms for high-risk or business-critical decision scenarios.
Organizations that approach this as a platform-scale process do so smoothly. Teams that add this as an afterthought have a tough year ahead.
6 Essential Best Practices to Scale AI Models in Production
Version Control for Models and Data
Code versioning alone won’t cut it for machine learning. Data, features, model artefacts, and prompts will all require versioning too. DVC (Data Version Control) and Git LFS are good at handling large data and model artefacts along with your codebase. Without versioning, reproducibility falls apart the second someone leaves the team.
Basic DVC configuration:
dvc init
dvc add data/training_set.csv
git add data/training_set.csv.dvc
git commit -m "Track training data v1.2"Use DVC alongside an experiment tracking tool like MLflow or Weights & Biases to store experiment metadata. Every model artefact should answer three basic questions: which data trained it, what code generated it, and what scores did it achieve.
Automated Model Training Pipelines
Manually training more than a handful of models is unsustainable. ML pipeline automation helps here by scaling out. Kubeflow Pipelines, Apache Airflow, and Prefect help define a machine learning pipeline as code. Each run is reproducible, scheduleable, and version-controlled.
Pipelines trigger on actual signals: drift thresholds crossed, model performance below some floor, or scheduled cadences for fast-paced domains. A recommendation system may retrain every week.
CI/CD for Machine Learning Models
The CI/CD pipeline for ML builds on that of software engineering by adding two more steps to the process, namely data validation and model validation. In your pipeline, you should build the model artifact, run unit tests, validate the data schema, train on the data set, evaluate the model candidate, and promote it if it outperforms the baseline.
stages:
- lint_and_test
- validate_data
- train_model
- evaluate_against_baseline
- deploy_to_staging
- canary_deploy_productionThe build blocks promotion of each stage. In one step, you’ve covered nearly all sources of production issues.
Model Monitoring and Drift Detection
Accuracy is vanity in production. Proper ML monitoring covers data drift, concept drift, prediction drift, latency, throughput, fairness, and cost per inference. For LLM-driven applications, we have hallucination rates, grounding scores, and human preference metrics.
Evidently AI, Arize, and WhyLabs are among the tools used in real-time detection of distribution shifts. Assign each alert to a dedicated engineer on call. According to McKinsey’s analysis, model decay results in millions of dollars in lost ROI in enterprise deployments annually.
Scalable Infrastructure with Containerization
Containerization allows portability, reproducibility, and elasticity in model deployment. Pack the model code and its dependencies in a Docker container. Run on top of Kubernetes for auto-scaling, reliability, and rolling deployments.
Basic model-serving Dockerfile:
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt.
RUN pip install --no-cache-dir -r requirements.txt
COPY model/ ./model/
COPY serve.py.
EXPOSE 8080
CMD ["python", "serve.py"]Consider combining your containers with serving libraries such as KServe, Seldon Core, and BentoML. These technologies provide the infrastructure for batching, GPU allocation, load balancing, and other essential features.
Model Governance and Compliance
Model governance cannot be reduced to bureaucracy. It refers to the documentation and transparency required to make the AI decisions trusted by regulators, customers, and stakeholders. Each production model must have a model card, a classification of the associated risks, an owner, and a retraining schedule.
Regulatory compliance requires role-based authorization, approval processes, and tracking. The EU AI Act imposes up to 7% fines on worldwide income for non-compliance. Proactively incorporating governance mechanisms into the pipeline is vastly more cost-effective.
How to Deploy AI Models at Scale?
Package the Model
Containerise the model, with all its dependencies, runtime, and version manifest, and treat it as immutable. The image that got through staging is the image running in production. Reproducible builds can be accomplished via Docker, Buildah, or Bazel. Tag every image with the model version, training data hash, and Git commit.
Validate Before Serving
Run shadow traffic testing, integration testing, and fairness testing before promotion. Shadow the new model’s predictions against the current one in production using live traffic without serving the new ones. Do not promote if any threshold is not met: accuracy, latency, fairness, or cost per inference. This is where unit tests fail you.
Choose the Serving Pattern
Pick the appropriate deployment based on your tolerance for latency, volume of data, and risk profile.
| Pattern | Latency Tolerance | Common Example | Operational Risk |
| Batch | Hours to days | Scoring/forecasting | Low |
| Real-Time API | Milliseconds | Fraud, recommendations, messaging apps | High |
| Streaming | Sub-second event processing | IoT, predictions, anomalies | High |
| Edge | Near-zero latency | Vision, offline commerce, medical devices | Medium |
In reality, most AI systems in production use at least two. Retailers will typically run batch scores and then re-rank customers in real-time.
Roll Out Progressively
Kick off the process with a 5% traffic load. Measure accuracy, latency, and error budgets for a certain period. Expand to 25%, then 50%, only after metrics remain in the safe zone. For mission-critical models, like healthcare or financial services, run both shadow and canary simultaneously. The shadow validates predictions quietly, while the canary validates their effect on users progressively.
Wire the Monitoring Layer
Track model drift, latency, fairness, and cost per inference from day one. Make sure every single alert has an assigned owner. Integrate monitoring into the incident response process, not another dashboard that people do not use. Tools such as Prometheus and Grafana will give you infrastructure-level monitoring. Evidently, or Arize will track your model-specific metrics. You need both.
Plan Rollback and Retraining
Pre-position the previous model version to roll back within seconds. Automate the drift alerts and make sure they automatically kickstart the retraining process if metrics exceed the pre-set threshold. A good rollback in 90 seconds will beat a clever fix in three days. Write a runbook for rollback before the incident, not during it.
Ready to scale your AI systems with confidence?
Connect with our AI integration and governance specialists today to build a reliable, production-ready MLOps framework that reduces operational complexity and accelerates deployment success.
Common MLOps Implementation Pitfalls
Models Built In Different Libraries/Languages/Stacks
Data scientists tend to use whatever framework they feel is the most efficient: scikit-learn, PyTorch, TensorFlow, XGBoost, and JAX, among others. Each of these frameworks has its serving format, dependency graph, and monitoring peculiarities. Hence, a zoo of individual deployments emerges that no one can maintain anymore.
Scaling AI/ML = Scaling Staff to Support AI
Every new model in production requires monitoring, retraining, incident handling, and periodic audits. Without the necessary platform infrastructure, operational costs will grow linearly with every additional model. Clever teams invert this growth function by investing in platforms such as feature stores, automated machine learning workflows, and self-service deployment of models.
Models Requiring Dynamic Endpoints
Some models require variable input parameters, varying combinations of features, and specific postprocessing for each request. Otherwise, hardcoding these rules in the serving layer will create fragile endpoints that will fail upon every change to the product specifications. Instead, use feature stores, dynamic configuration, and routing layers such as KServe or Seldon.
Lack of AI Governance
Untagged models, unclaimed models, and models with no audit log are potential disasters waiting to happen. If regulators ever ask why a loan application was declined or a claim was flagged, “because the model said so” is never a satisfactory answer. Therefore, include governance capabilities in your data pipeline.
The Bottom Line
MLOps is the field where investments in AI result in success. It’s not the most complex algorithms that win on the production side; it’s versioning, automation, monitoring, and accountability. Following ML best production practices can no longer be an option but rather a matter of survival for small businesses and startups. At Pinnasys, our AI integration and governance specialists help founders manage their ML systems sustainably. Interested in deploying ML successfully? Let’s talk to our AI architects about your MLOps strategy.
Key Takeaways from the Article
- ML projects tend to break in production but not during R&D phases.
- Versioning, automation, and monitoring comprise the true MLOps core.
- Make sure to match deployment patterns with latency, volumes, and risks.
- Data, model behavior, and performance should be monitored together.
- Strong ownership is more important than smart solutions.
Frequently Asked Questions About MLOps Best Practices
How is MLOps different from LLMOps?
MLOps covers the full lifecycle for traditional ML models. LLMOps adds prompt versioning, RAG pipeline monitoring, hallucination detection, eval frameworks, and token cost tracking. LLMOps is a specialized layer on top of MLOps, not a replacement for it.
What team size do you need to run MLOps in production?
Less than you might think. Two people: one ML engineer and one platform engineer, suffice to create a functional MLOps infrastructure. That applies to fewer than ten models. If you have more, then separate platform, data, and governance roles are required.
Which MLOps tools work best for a small AI team?
The most common tool stack for small organizations includes either MLflow or Weights and Biases for experiment management. Combined with a managed serving layer (SageMaker, Vertex AI, Databricks) and basic monitoring using Evidently or Arize.
How often should production AI models be retrained?
It depends on domain velocity. Fraud and e-commerce models often retrain weekly or daily. Compliance and risk scoring models retrain monthly or quarterly. Trigger retraining on drift thresholds when possible, not just calendar schedules.
Is MLOps necessary for SMBs running just two or three models?
Yes, in a lighter form. You still face drift, retraining, and audits regardless of the number of models. Start with a minimal stack for your first few models: versioning, monitoring, and one rollback path. Extend as the number grows.